There is no question that massive data is being generated in greater volumes than ever before. Along with the traditional data set, new data sources as sensors, application logs, IOT devices, and social networks are adding to data growth. Unlike traditional ETL platforms like Informatica, ODI, DataStage that are largely proprietary commercial products, the majority of Big ETL platforms are powered by open source.
With many execution engines, customers are always curious about their usage and performance.
To put it into perspective, In this post I am running set of query against 3 key Query Engines namely Tez, MapReduce, Spark (MapReduce) to compare the query execution timings.
create external table sensordata_csv ( ts string, deviceid int, sensorid int, val double ) row format delimited fields terminated by '|' stored as textfile location '/user/sranka/MachineData/sensordata' ; drop table sensordata_part; create table sensordata_part ( deviceid int, sensorid int, val double ) partitioned by (ts string) clustered by (deviceid) sorted by (deviceid) into 10 buckets stored as orc ; "**********************************************" "** 1) Baseline: Read a csv without Tez" " set hive.execution.engine=mr" " select count(*) from sensordata_csv where ts = '2014-01-01'" "**********************************************" 2016-02-25 02:57:27,444 Stage-1 map = 0%,  reduce = 0% 2016-02-25 02:57:35,880 Stage-1 map = 100%,  reduce = 0%, Cumulative CPU 2.84 sec 2016-02-25 02:57:44,420 Stage-1 map = 100%,  reduce = 100%, Cumulative CPU 4.99 sec MapReduce Total cumulative CPU time: 4 seconds 990 msec Ended Job = job_1456183816302_0046 MapReduce Jobs Launched: Job 0: Map: 1  Reduce: 1   Cumulative CPU: 4.99 sec   HDFS Read: 3499156 HDFS Write: 6 SUCCESS Total MapReduce CPU Time Spent: 4 seconds 990 msec OK 16733 Time taken: 32.524 seconds, Fetched: 1 row(s) "**********************************************" "** 2) Read a csv with Tez" " set hive.execution.engine=tez" " select count(*) from sensordata_csv where ts = '2014-01-01'" "**********************************************" Total jobs = 1 Launching Job 1 out of 1 Status: Running (application id: application_1456183816302_0047) Map 1: -/- Reducer 2: 0/1 Map 1: 0/1 Reducer 2: 0/1 Map 1: 0/1 Reducer 2: 0/1 Map 1: 0/1 Reducer 2: 0/1 Map 1: 1/1 Reducer 2: 0/1 Map 1: 1/1 Reducer 2: 1/1 Status: Finished successfully OK 16733 Time taken: 16.905 seconds, Fetched: 1 row(s) "**********************************************" "** 3) Read a partition with Tez" " select count(*) from sensordata_part where ts = '2014-01-01'" "**********************************************" Total jobs = 1 Launching Job 1 out of 1 Status: Running (application id: application_1456183816302_0047) Map 1: -/- Reducer 2: 0/1 Map 1: 0/2 Reducer 2: 0/1 Map 1: 1/2 Reducer 2: 0/1 Map 1: 2/2 Reducer 2: 0/1 Map 1: 2/2 Reducer 2: 1/1 Status: Finished successfully OK 16733 Time taken: 6.503 seconds, Fetched: 1 row(s) "**********************************************" "** 4) Read a partition with Spark" " select count(*) from sensordata_part where ts = '2014-01-01'" "**********************************************" Time taken: took 5.8 seconds "**********************************************" "** 5) Read a csv with Spark" " select count(*) from sensordata_csv where ts = '2014-01-01'" "**********************************************" Time taken: took 4.5 seconds
Query 1 –select count(*) from sensordata_csv where ts = ‘2014-01-01’
Query 2–select count(*) from sensordata_part where ts = ‘2014-01-01’
Below tables shows the execution timings :
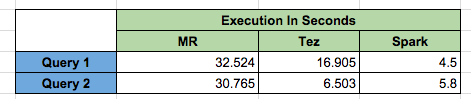
Conclusion Which Engine is right :
Spark being In memory execution engine comes out to be a clear winner, but in certain scenario especially in the current scenario of running query on partition table TEZ execution engines comes closer to spark.
With this you can not conclude that you Spark will solve your — World Hunger Problem — of Big ETL, being continuously growing product Spark has its own challenges when it comes to productization of the Spark workload, same holds True with TEZ. In all MR engine has been around for the most time and its been the core of HDFS framework, for mission critical workloads which are not time bound, MR could be the best choice.
Hope This Helps
Sunil S Ranka
About Spark : http://spark.apache.org/
About MapReduce : https://en.wikipedia.org/wiki/MapReduce
About Tez : https://tez.apache.org/

