With my recent role as CTO/Advisor with www.analytos.com, during most of my conversation with Analytics leaders within the company, all are concern over security. At a recent conversation with another entrepreneur friend, one of his solution was stalled due to SQL injection issue on the cloud ( a valid concern , but is it valid ?) .
During my recent startup sting, cloud Allergy word was coined, and it did make sense, because allergies do exist and you need to go past them , and need to worry about the only life threating ones.
My Early Internet Days
I remember the year 1996 , when I had created my 1st email address — coolguy123@yahoo.com –, 20 years back we were apprehensive about using our real name as part of the email address, now past 20 years, only hackers and late night chat rooms create fake ids. In the year 2001, when I got my 1st credit card ( $500 credit limit ), using it for online shopping was a taboo, in fact till mid of 2005 I had paid my PG&E bill in person at the authorized facility . With the mindset, The fear was not to use personal or financial information over the public internet.
Changing Notion
Come the year 2013 ( within 15 years ) , using a credit card is a norm, giving credit card number to a Comcast agent seating overseas is a trivial and nonissue. With the notion of facebook, whatsApps, SnapChat and many more social Apps, we take pride and effort to share personal and important moments with our — extended Social Families — (Yes, just coined a new word ). With google search data retention capability, I tell my customer — Google Knows you more than your Wife or partner — Most of us take backup of most important documents by sending via email to yourself.
Most importantly kp.org (Kaiser Permanente, a leading national HMO) has all the personal information about your recent visits, vaccination and secured messaging through their enhanced portal .
With the mobile banking capability taking a photo of cheque and depositing is just another norm.
With the changing notion, we will go past the – cloud allergy — behaviour and some of the security questions and concerns will be trivial or non-issue.
Giant Cloud Providers and Security Capabilities
At times if you look at the public clouds, AWS, Google, and MS Azure, these giants are able to attract more talented individuals than most of the companies small to mid-size companies. With cloud being their core focus, they have hundreds of brilliant minds dedicated to security. A company with a modest budget can not match the level of expertise prominent cloud providers can spend on security. Unlike earlier, Fast Deployment, Lower Costs, and Rapid Time to Value have assumed advantages of cloud, security will/is achieving the same level of confidence.
Public clouds at times are much safer than the internal network ( Sony and Target hacking were the best example we all can use )
Trust in and adoption of cloud computing continues to grow despite persistent cloud-related security and compliance concerns. Such is the overarching takeaway of Intel Security’s recent report, “Blue Skies Ahead? The State of Cloud Adoption.” – See more at http://www.baselinemag.com/cloud-computing/slideshows/cloud-deployments-grow-despite-security-concerns.html#sthash.nXNytNaT.dpuf
Different Cloud Service Models :
With the evolving nature of the cloud, Understanding the relationships and dependencies between different cloud servicing models are critical to understanding cloud computing security risks. IaaS is the foundation of all cloud services, with PaaS building upon IaaS, and SaaS, in turn, building upon PaaS as described in the Cloud.
** Infrastructure as a Service (IaaS), delivers computer infrastructure (typically a platform virtualization environment) as a service, along with raw storage and networking. Rather than purchasing servers, software, data-center space, or network equipment, clients instead buy those resources as a fully outsourced service.
** Software as a service (SaaS), sometimes referred to as “on-demand software,” is a software delivery model in which software and its associated data are hosted centrally (typically in the (Internet) cloud) and are typically accessed by users using a thin client, normally using a web browser over the Internet.
** Platform as a service (PaaS), is the delivery of a computing platform and solution stack as a service. PaaS offerings facilitate deployment of applications without the cost and complexity of buying and managing the underlying hardware and software and provisioning hosting capabilities. This provides all of the facilities required to support the complete life cycle of building and delivering web applications and services entirely available from the Internet.
** Definitions are taken from the internet.
** The figure below shows an example of how a cloud service mapping can be compared against a catalogue of compensating controls to determine which controls exist and which do not — as provided by the consumer, the cloud service provider, or a third party. This can, in turn, be compared to a compliance framework or set of requirements such as PCI DSS, as shown.
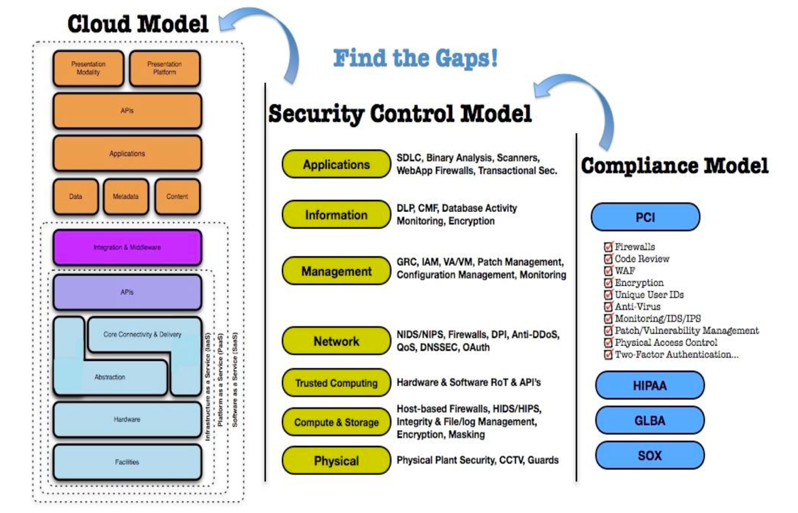
** Mapping the Cloud Model to the Security Control & Compliance
** Text and Figure Taken from CSA (Cloud Security Alliance).
Conclusion:
Customer needs to be made aware of what they are considering moving to the cloud. Not every dataset moved to the cloud, needs the same level of security. For low critical dataset, lower security can be used. For a high-value dataset with audit, compliance requirement might entail audit and data retention requirements, for high-value dataset with no regularity compliance restrictions, there could me need for more technical security than the data retention. In short, there would be always a place for all type of dataset in the cloud.